Configuring Tag History
Logging data is easy with Tag Historian. Once you have a database connection, all you do is set the Tags to store history and Ignition takes care of the work. Ignition creates the tables, logs the data, and maintains the database.
The historical Tag values pass through the store-and-forward engine before ultimately being stored in the database connection associated with the historian provider. The data is stored according to its data type directly to a table in the SQL database, along with its quality and a millisecond resolution timestamp. The data is only stored on-change, according to the value mode and deadband settings on each Tag, thereby avoiding duplicate and unnecessary data storage. The storage of scan class execution statistics ensures the integrity of the data.
The first step to storing historical data is to configure Tags to record values. This is done from the History section of the Tag Editor in the Designer. Select the History Enabled property to turn on history. The properties include an Historical Tag group that will be used to check for new values. Once values surpass the specified deadband, they are reported to the history system, which then places them in the proper store and forward engine. Complete information on the History properties (and all properties in the Tag Editor), can be found on the Tag Properties Table.

Enable History on a Tag
The following example demonstrates how to configure a tag to store values into the Tag Historian.
Dataset type tags are not supported by the Tag History system.
-
In the Tag Browser, select one or more Tags. For example, we selected several Sine Tags in the Sine folder.
-
Right-click on the selected Tags, and then select Edit Tag
 . The Tag Editor window is displayed. Here, you can edit the Tag and change the name, data type, scaling options, metadata, permissions, history, and alarming.
. The Tag Editor window is displayed. Here, you can edit the Tag and change the name, data type, scaling options, metadata, permissions, history, and alarming.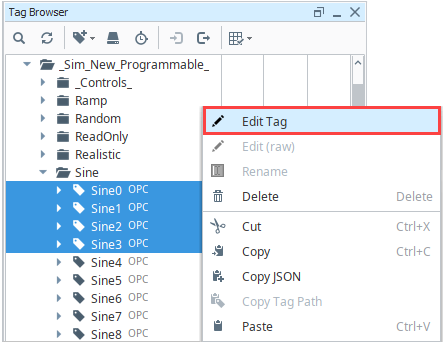
-
Scroll down to the History section of the Tag Editor. Select the History Enabled check box.
-
Choose a database (for example, MySQL) from the Storage Provider dropdown.
-
Set the Sample Mode to Tag Group.
-
Set the Historical Tag Group to Default Historical.

-
Click OK. Now look in the Tag Browser. To the right of each Sine Tag that is storing history, a History
 icon appears letting you know it is set up.
icon appears letting you know it is set up.
If you were to look in your database, you can see all the tables and data Ignition has created for you.
Setting a UDT to Log History Data
Enabling tag history on members in a UDT involves editing the UDT definition, and enabling history on the any members you wish to record. These history settings will then propagate to members in any instances.
Tag History Configuration
Below is a description of some important tag history settings
Sample Mode
The Sample Mode setting determines how often a historical record should be collected.
- On Change - Collects a record whenever the value on the Tag changes.
- Periodic - Collects a record based on the Sample Rate and Sample Rate Units properties.
- Tag Group - Collects a record based on the Tag Group specified under the Historical Tag Group property.
Historical Tag Group Historical Tag Group setting shows up with Sample Mode is set to Tag Group. Historical Tag Group setting determines how often to record the value on the Tag. It uses the same Tag Groups that dictate how often your Tags should execute. Typically, the Historical Tag Group should execute at the same rate as the Tag's Tag Group or slower: if a Tag's Tag Group is set to update at a 1,000ms rate, but the Historical Tag Group is set to a Tag Group that runs at 500ms rate, then the Tag History system will be checking the Tag's value twice between normal value changes, which is unnecessary.
Max and Min Time Between Samples
Normally Tag Historian only stores records when values change. By default, an "unlimited" amount of time can pass between records – if the value doesn't change, a new row is never inserted in the database. By modifying these settings, it is possible to specify the maximum number of scan class execution cycles that can occur before a value is recorded. Setting the value to 1, for example, would cause the Tag value to be inserted each execution, even if it has not changed. Given the amount of extra data in the database that this would lead to, it's important to only change this property when necessary.
Deadband and Analog Compression
The deadband value is used differently depending on whether the Tag is configured as a Discrete Tag or as an Analog Tag. Its use with discrete values is straightforward, registering a change any time the value moves +/- the specified amount from the last stored value. With Analog Tags, however, the deadband value is used more as a compression threshold, in an algorithm similar to that employed in other Historian packages. It is a modified version of the 'Sliding Window' algorithm. Its behavior may not be immediately clear, so the following images show the process in action, comparing a raw value trend to a "compressed" trend.
The Deadband Style property sets the: Auto, Analog, or Discrete.
Discrete
Storage
The deadband will be applied directly to the value. That is, a new value (V1) will only be stored when: |V1-V0| >= Deadband.
Interpolation
The value will not be interpolated. The value returned will be the previous known value, up until the point at which the next value was recorded.
Analog
Storage
Every time the tag's value changes, this method will calculate upper and lower slope values. These slope values are stored in memory, and are ultimately used to determine when a new value is stored. The calculations used are listed below:
(((NewValue + Deadband) - PreviousValue) / (NewTimestamp - PreviousTimestamp))
(((NewValue - Deadband) - PreviousValue) / (NewTimestamp - PreviousTimestamp))
The algorithm will only store new values under the following conditions:
- The system always stores the first value on the tag when using the method, since the subsequent values will need an initial value to calculate slope from.
- If the newly calculated upper slope is lower than the previously calculated lower slope value, the system will store the new value.
- If the newly calculated lower slope is larger than the previously calculated upper slope value, the system will store the new value.
- The system always stores a value when the quality on the tag changes.
In cases where a new value isn't stored, the system will compare the newly calculated slope values to the previously calculated values:
- If the new upper slope is less than the previous upper slope, then the new upper slope is used for future comparisons.
- If the new lower slope is greater than the previous lower slope, then the new lower slope is used for future comparisons.
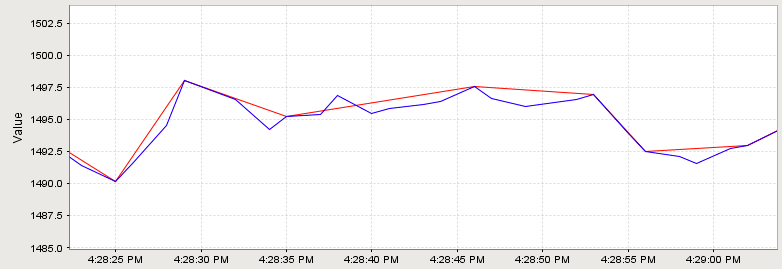
In the image below, an analog value has been stored. The graph has been zoomed in to show detail; the value changes often and ranges over time +/- 10 points from around 1490.0. The compressed value was stored using a deadband value of 1.0, which is only about .06% of the raw value, or about 5% of the effective range. The raw value was stored using the Analog mode, but with a deadband of 0.0. While not exactly pertinent to the explanation of the algorithm, it is worth noting that the data size of the compressed value, in this instance, was 54% less than that of the raw value.
Interpolation
The value will be interpolated linearly between the last stored value and the next value. For example, if the value at Time0 was 1, and the value at Time2 is 3, selecting Time1 will return 2.
Example
Let's look at a demonstration of how the analog compression works. For this example we'll assume a tag is using a historical deadband value of 0.01. Over the course of a few moments the tag's value changed several times, as represented on the chart below.

The tag historian system stores the records into one of the data partitions. After the value changes above, our database shows the following records.
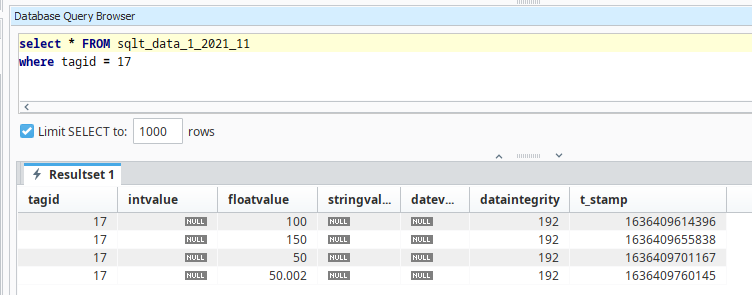
Using the information above, we'll describe how each value was stored as the tag changed value.
Value A
Once we enable history on the tag and set the deadband mode to Analog, the system will record the first value on the tag. Since we only have our first value, we use arbitrarily large and small values for the upper slope and lower slope (3.40282347 x 10^38 and -3.40282347 x 10^38, respectively), and store those numbers until the tag changes value again.
Value B
Here we see the value on the tag changed to 150. Since this is only the second value recorded, the system needs to figure out the slope values so it knows when to next collect a record. The system calculates both slope values as listed above.
// Upper Slope
((150 + 0.01) - 100) / (1636409655838 - 1636409614396)
(150.01 - 100) / 41442
50.01 / 41442
0.001206768
// Lower Slope
((150 - 0.01) - 100) / (1636409655838 - 1636409614396)
(149.99 - 100) / 41442
49.99 / 41442
0.0012062641
Because the previously stored slope values are simply placeholders, we replace them with these newly calculated values. This value of 150 is not yet stored in the database. Instead, this value of 150 is kept in memory, waiting until the tag changes again.
Value C
Our tag changes value to 50. The system calculates the new slope values again, this time using 150 as the previous value.
// Upper Slope
((50 + 0.01) - 150) / (1636409701167 - 1636409655838)
(50.01 - 150) / 45329
-99.99 / 45329
-0.0022058727
// Lower Slope
((50 - 0.01) - 150) / (1636409701167 - 1636409655838)
(49.99 - 150) / 45329
-100.01 / 45329
-0.002206314
Our newly calculated values meet our storage criteria. The new upper slope (-0.0022058727) is less than the previous lower slope (0.0012062641). Therefore the system will store the previous value (150) and use these newly calculated slope values the next time the tag changes value. The newest value of 50 is not yet stored.
Value D
Our tag changes to a value of 50.001. As usual, the system calculates some new slope values.
// Upper Slope
((50.001 + 0.01) - 50) / (1636409726809 - 1636409701167)
(50.011 - 50) / 25642
0.011 / 25642
4.289837E-7
// Lower Slope
((50.001 - 0.01) - 50) / (1636409726809 - 1636409701167)
(49.991 - 50) / 25642
-0.009 / 25642
-3.5098665E-7
Our new lower slope is larger than our previously stored upper slope. We record the previous value of 50 and keep our new slope values in memory.
Value E
Our tag changes to a value of 50.002. We calculate new slope values.
// Upper Slope
((50.002 + 0.01) - 50) / (1636409760145 - 1636409701167)
(50.012 - 50) / 58978
0.012 / 58978
2.034657E-7
// Lower Slope
((50.002 - 0.01) - 50) / (1636409760145 - 1636409701167)
(49.992 - 50) / 58978
-0.008 / 58978
-1.356438E-7
These new slope values do not meet our storage criteria: the new upper slope is not less than the previous lower slope, and the new lower slope isn't greater than the previous upper slope. Thus, the previous tag value of 50.001 is not stored since it's too similar to the current value of 50.002.
In addition, the system does notice that the new upper slope is less than the old upper slope, and the new lower slope is greater than the old lower slope. So the system deems the new slope values to be more restrictive, and will use those the next time the tag value changes. The system will use the newly calculated slope values when evaluating the next value change.
Value F
Our tag changes to a value of 100. New slope values are calculated, using the most recent value of 100 compared to the previous value of 50.002.
// Upper Slope
((100 + 0.01) - 50.002) / (1636409786810 - 1636409760145)
(100.01 - 50.002) / 26665
50.008 / 26665
0.0018754172
// Lower Slope
((100 - 0.01) - 50.002) / (1636409786810 - 1636409760145)
(99.99 - 50.002) / 26665
49.988 / 26665
0.0018746671
The new lower slope is greater than the previous lower slope, so the previous value (50.002) is stored. This process repeats indefinitely.
Auto
The setting will automatically pick either Analog or Discrete, based on the data type of the Tag.
- If the data type of the Tag is set to a float or double, then Auto will use the Analog Style.
- If the data type of the Tag is any other type, then the Discrete style will be used.
Seeded Values
Tag history queries sometimes use seeded values (occasionally called "Boundary Values"). When retrieving tag history data, the system will also retrieve values just outside of the query range (before the start time, after the end time), and include them in the returned result set. They're generally used for interpolation purposes. If the tag is storing history with an Analog Value Mode, or "Prevent Interpolation" is enabled on the calling query, then these seeded values will not be included.
Pre-Query Seed Value
These are a single value taken from just before the start of the query range. The value and timestamp for this value is typically the first row in the resulting query. Pre-query seed values are always included when not using a raw data query.
An exception to this rule is can be found with the system.tag.queryTagHistory function. Setting includingBoundingValues argument to True and returnSize to -1 will return a raw data query with a pre-query seed value.
Post-Query Seed Value
These extra values are added to the end of the result set, representing the next data point after the query range. Post-query seed values are only included when interpolation is requested/enabled for the query. Thus, values stored with a Discrete deadband style will not include post-query seed values in the query results.
If the system knows the query is retrieving records for a tag on the local system, this value will be determined by the current tag's value instead of retrieving the last recorded value in the database. The current tag's value is also used in cases where the time range extends to the present time.
If a result in a query is outside of the requested range, the value is typically a seeded value. This typically occurs when the range is so small that values were not recorded, or when the range is in the future (and thus values have not yet been recorded).
Raw Data Queries
In most cases queries returned by tag history will apply some form of aggregation. However it is possible to get a "raw data query", which is a result set that contains only values that were recorded: meaning no aggregation or interpolation is applied to the results. A raw data query can be obtained by using one of the following options:
- Set the Sample Size on Vision Tag History bindings to On Change
- Setting the returnSize parameter on system.tag.queryTagHistory or system.tag.queryTagCalculations to -1
- Settting the Query Mode on Perspective Tag History bindings to AsStored