Types of Groups
The SQL Bridge Module provides four different types of Transaction Groups that you can use in your projects. Each of these different types of groups vary in their operation and use for data logging and database to PLC synchronization.
Standard Group
The Standard Group contains items, which may be mapped to columns in the group's linked database table, or used internally for features such as triggering or handshakes. Items that are mapped to the database target a specific column of a single specific row, chosen according to the group settings. Values can flow from the items into the database, from the database to the items, or bidirectionally, allowing the value of the database and the item will be synchronized.
The group may also insert new rows instead of updating a specific row, similar to the Historical Group.
Group Settings
The Standard Group uses a timer-based execution model shared by all groups, and the normal trigger settings. Additionally, there are several settings specific to the group type:
- Automatically create table - If the target table does not exist, or does not have all of the required columns, it will be created/modified on group startup. If not selected and the table doesn't match, an error will be generated on startup.
- Use custom index column - If selected, you may enter any column name to hold the index. If unselected, the table index will be named <table name>_ndx.
- Store timestamp to - Specifies whether or not to store a timestamp with the record, and the target column. The timestamp will be generated by the group during execution. For groups that update a row, the timestamp will only be written if any of the values in the group are also written.
- Store quality code to - If selected, stores an aggregate quality for the group to the specified column. The aggregate quality is the combined quality of all of the items that write to the table. For more information about quality values, see Data Quality.
- Delete records older than - If selected, records in the target table will be deleted after they reach the specified age. This setting is useful for preventing tables from growing in an unbounded manner, which can cause disk space and performance problems over time.
Table Action
This section details how the group interacts with the table on each execution. The group can insert a new row, or select/update the first, last or a custom record.
- Insert New Row - This option will make the group insert a new record into the database every time the group executes. This is the forced behavior of the Historical Group.
- Update/Select - This option will either update or select from matching rows based on the option selected below it. The Update Mode property above determines whether an update (OPC to DB), select (DB to OPC), or both (Bi-directional) are used when the group executes.
- First - Use the first row in the table. It is not recommended to use this option unless the order of the data in the table is guaranteed.
- Last - Use the last row in the table. This is commonly used when another group (or another program) is inserting new rows for us, and we always want to update the most recent record.
- Custom - A custom update clause is essentially the WHERE clause of the SQL query that will be generated to read and write the group data. This usually contains a reference to a tag in the group. IE: column_name =
{[~]item_name} - Key/Value Pairs - Used to inject dynamic values in order to create a WHERE clause for you. The table below this option will allow you to enter column names and link them to values (usually tags in the group). This option also has the ability to Insert a new row with the current key/value pair if it was not found.
Typical Uses
Standard Groups can be used any time you want to work with a single row of data. This can include:
- Historical logging - Set the group to insert new records, and log data historically either on a timer, or as the result of a trigger. Flexible trigger settings and handshakes make it possible to create robust transactions.
- Maintain status tables - Keep a row in the database updated with the current status values. Once in the database, your process data is now available for use by any application that can access a database, dramatically opening up possibilities.
- Manage recipes - Store recipe settings in the database, where you have a virtually unlimited amount of memory. Then, load them into the PLC by mapping DB-to-OPC using a custom where clause with an item binding in order to dynamically select the desired recipe.
- Sync PLCs - Items in the group can be set to target other items, both for one-way and bidirectional syncing. By adding items from multiple PLCs to the group, you can set the items of one PLC to sync with the others. By creating expression items that map from one PLC item to the other, you can manipulate the value before passing it on.
Historical Group
The Historical Group inserts records of data into a SQL database, mapping items to columns. Full support for triggering, expression items, hour & event meters and more means that you can also set up complex historical transactions. Unlike the Standard Group, the Historical Group cannot update rows, only insert. It also cannot write back to items (besides trigger resets and handshakes).
Group Settings
The settings of the Historical Group are identical to the settings in the Standard Group, but limited to inserting rows.
Typical Uses
- Basic Historical Logging - Recording data to a SQL database gives you incredible storage and querying capabilities, and makes your process data available to any application that has DB access.
- Shift Tracking - Use an expression item to track the current shift based on time, and then trigger off of it to record summary values from the PLC. Use a handshake to tell the PLC to reset the values.
Block Group
Block Groups instead allow you to store your data in a tall format. They allow you to create a unique type of item, called a Block Item, which represents an ordered list of values to store within a column for each execution.
General Description
A Block Group contains one or more block items. Each block item maps to a column in the group's table, and then defines any number of values (OPC or SQLTag items) that will be written vertically as rows under that column. The values may be defined in the block item in two modes. The first, List mode, lets a list of value-defining items to be entered. These value items may either be OPC items, tag items, or static values. The second mode, Pattern mode, can be useful when OPC item paths or tag paths contain an incrementing number. You may provide a pattern for the item's path, using the wildcard marker {?} to indicate where the number should be inserted.
Block groups are very efficient, and can be used to store massive amounts of data to the database (for example, 100 columns each with 100 row -10,000 data points- will often take only a few hundred milliseconds to write, depending on the database). They are also particularly useful for mirroring array values in the database, as each element will appear under a single column, and share the same data type.
Like the Standard Group, the Block Group can insert a new block, or update the first, last or a custom block. Additionally, the group can be set to only insert rows that have changed in the block.
In addition to block items, the group can have other OPC items, tag references, and Expression items. These items can be used for triggers, handshakes, etc. They may also target a column to be written, and will write their single value to all rows in the block.
The block group is so named because it writes "blocks" of data to a database table, consisting of multiple rows and columns.
Typical Uses
Block Groups are useful in a number of situations where you need to deal with a lot of data efficiently. Mirroring/Synchronizing array values to DB - Arrays are often best stored vertically, which makes them perfect for Block Groups. Pattern mode makes configuration a breeze by allowing to you specify the array as a pattern, and set the bounds.
- Recipe management - Like Standard Groups, but used when set points are better stored vertically than horizontally.
- Vertical history tables - Group data points by data type (integer, float, string), create a copy of the item that stores item path, and then use the insert changed rows option to create your own vertically storing historical tables. Create additional copies of the block item that refer to quality and timestamp in order to get further information about the data point.
Table Format
Due to their nature, Block Groups store records in a different format than the other groups. Consider how other Transaction Groups work. A single execution of a Standard or Historical Group would store a row that looked like the following:
| table_ndx | tag1 | tag2 | tag3 |
|---|---|---|---|
| 1 | 10 | 20 | 30 |
We could take the tags from the above example, and place them in under a single block item:
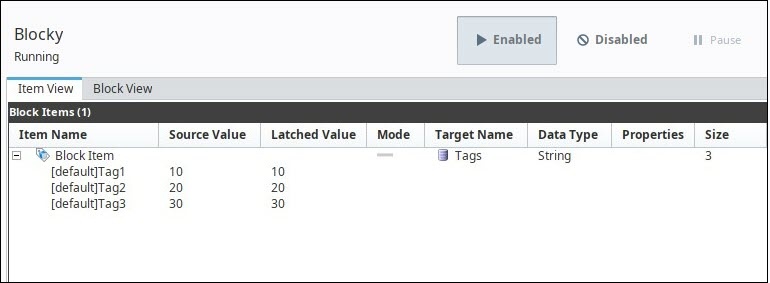
Under a single block item, each tag is nested under the block item, and the block item is targeting the "Tags" column under Target name. A single execution of this group stores the records in our table as so:
| table_ndx | Tags |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 3 | 30 |
Each additional block item would store records as a separate column.
| table_ndx | Tags | More_Tags |
|---|---|---|
| 1 | 10 | 11 |
| 2 | 20 | 22 |
| 3 | 30 | 33 |
Row ID and Block ID
Using the same tag examples from above, if we kept inserting new rows at every execution, our table would start to look like the following:
| table_ndx | Tags |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 3 | 30 |
| 4 | 15 |
| 5 | 25 |
| 6 | 35 |
This isn't ideal, since the table doesn't have a great way to show which value came from which tag. To help with this, Block Groups have optional row_id and block_id columns that can be enabled (see the "Store row id" and "Store block id" settings under Group Settings). If we enable both the Block ID and Row ID, our table would look like the following:
| table_ndx | Tags | row-id | block_id |
|---|---|---|---|
| 1 | 10 | 0 | 1 |
| 2 | 20 | 1 | 1 |
| 3 | 30 | 2 | 1 |
| 4 | 15 | 0 | 2 |
| 5 | 25 | 1 | 2 |
| 6 | 35 | 2 | 2 |
Block ID represents the a single execution of the group, meaning rows with the same block_id value were inserted together. We see block_id values of 1 (rows 1-3) are part of the same execution, and rows with a block_id value of 2 (rows 4-6) are a separate execution.
Row ID in an index representing which item in the block item the row corresponds to. In our example, Tag1 is the first or top item in the block item (row index 0), Tag2 is next (row index 1), and Tag3 is last (row index 2). Now we know that any value on that table with a row_id of 0 came from Tag1.
Group Settings
Beyond the differences in the data, namely that the Block Group works with multiple rows instead of just 1, this group type shares many similarities with the Standard Group.
The unique settings are:
- Automatically create table - If the target table does not exist, or does not have all of the required columns, it will be created/modified on group startup. If not selected and the table doesn't match, an error will be generated on startup.
- Automatically create rows - If the target rows do not exist, they will be created on group execution. If not selected and the rows don't match, no records will be updated.
- Use custom index column - If selected, you may enter any column name to hold the index. If unselected, the table index will be named <table name>_ndx.
- Store timestamp to - Specifies whether or not to store a timestamp with the record, and the target column. The timestamp will be generated by the group during execution. For groups that update a row(s), the timestamp will only be written if any of the values in the group are also written.
- Store quality code to - If selected, stores an aggregate quality for the row to the specified column. The aggregate quality is the combined quality of all of the items that write to that row. For more information about quality values, see Data Quality.
- Store row id - Each row will be assigned a numeric id, starting at 0. If selected, this id will also be stored with the data.
- Store block id - If selected, an incremental block id will be stored along with the data. This number will be 1 greater than the previous block id in the table.
- Delete records older than - If selected, records in the target table will be deleted after they reach the specified age. This setting is useful for preventing tables from growing in an unbounded manner, which can cause disk space and performance problems over time.
Table Action
This section details how the group interacts with the table on each execution, and is not available for the Historical Group type. This means when the Timer or Schedule is active, and the Trigger condition are met. The group can insert a new row, or update the first, last or a custom record.
- Insert New Block - If selected, each row of the block will be inserted when the group executes, even if the data has not changed.
- Insert changed rows - This option will only insert the rows that have new data when the group executes. This is particularly useful for recording history for many data points on an "on change" basis, provided there is a unique id column defined. The "store row id" feature is useful for this, as well as the ability to reference the item path in an item's value property.
- Update / Select - This option will either update or select from matching rows based on the option selected below it. The Update Mode property above determines whether an update (OPC to DB), select (DB to OPC), or both (Bi-directional) are used when the group executes.
- First - Use the first row in the table. It is not recommended to use this option unless the order of the data in the table is guaranteed.
- Last - Use the last row in the table. This is commonly used when another group (or another program) is inserting new rows for us, and we always want to update the most recent record.
- Custom - Like Standard Groups, this setting allows you to target a specific section of the table, using SQL where clause syntax, with the ability to bind to dynamic item values. Unlike Standard Groups, however, the WHERE clause specified should result in enough rows to cover the block. Excess rows will not be written to, but fewer rows will result in a group warning indicating that some data could not be written.
Stored Procedure Group
The Stored Procedure Group lets you quickly map values bi-directionally to the parameters of a stored procedure. It is similar to the other groups in terms of execution, triggering, and item configuration. The primary difference is that unlike the other group types, the target is not a database table, but instead a stored procedure.
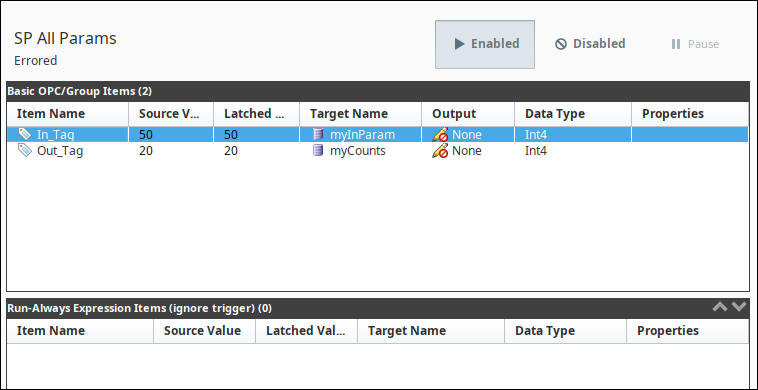
Items in the group can be mapped to input (or inout) parameters of the procedure. They also can be bound to output parameters, in which case the value returned from the procedure will be written to the item. Items can be bound to both an input and output at the same time.
Parameters may be specified using either parameter names or numerical indices. That is, in any location where you can specify a parameter, you can either use the name defined in the database, or a 0-indexed value specifying the parameter's place in the function call.
You cannot mix names and indices. That is, you must consistently use one or the other.
If using parameter names, the names should not include any particular identifying character (for example, "?" or "@", which are used by some databases to specify a parameter).
Group Settings
The Stored Procedure Group's settings look and act the same as those of the Historical Group. The primary difference, of course, is that instead of specifying a table name and column names, you'll specify a Stored Procedure and its parameters.
- Store timestamp to - Specifies whether or not to store a timestamp with the record, and the target column. The timestamp will be generated by the group during execution. For groups that update a row, the timestamp will only be written if any of the values in the group are also written.
- Store quality code to - If selected, stores an aggregate quality for the group to the specified column. The aggregate quality is the combined quality of all of the items that write to the table. For more information about quality values, see see Data Quality.
- Procedure Name - The name of the Stored Procedure (SP) that you will be using. You must look into the SP definition to see what inputs and outputs are available.
Typical Uses
- Call stored procedures - The Stored Procedure Group is the obvious choice when you want to bind values to a stored procedure. It can also be used to call procedures that take no parameters (though this can also be accomplished from Expression Items/SQLTags).
- Replace RSSQL - The Stored Procedure Group is very popular among users switching from RSSQL, given that application's heavy use of stored procedures.
Known Issues
When using an Oracle or PostgreSQL database, you must use indexed parameters.
Parameters in the Stored Procedure Group
When using a Stored Procedure Group, parameters may be configured to each item based on the type of the parameter:
- The Target Name column is used for writing, so specifying an IN or INOUT parameters under this column will have the item try to write its value to the parameter
- The Output column is used to move the value of an OUT or INOUT parameter into an item in the group. If an item in a group is configured to reference an OUT parameters, its Target Name value should be set to Read-Only.